
准备条件
- linux 系统,可以是实体 linux 系统也可以是虚拟机也可以是云服务器。虽说 docker 可以实现在一个 linux 系统中安装多个独立 Hadoop,但听说有 bug,而且企业里一般不会用 docker 实现 Hadoop。
- 确保 linux 系统防火墙关闭,IP 地址为同一网关下的固定地址。
- 已安装好 Java8,并配置好环境。
- 已安装好 Hadoop,本文使用的版本是 2.7.2。
- Hadoop 官方文档写的很详细,本文也基本按这个教程来,英语好的可以直接看教程。(http://hadoop.apache.org/docs/r2.7.2/)
- (可选)需要频繁在三个 linux 之间来回登录授权,不胜其烦。最好在三个 linux 之间配置一下 ssh 免密登录。
单机模式
单机模式是伪分布式,也就是只有一个节点的分布式系统。下面从 hadoop 介绍开始说起。
参考文档:(http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html)
hadoop 目录结构
- bin 目录:存放对 Hadoop 相关服务(HDFS,YARN)进行操作的脚本;
- etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件;
- lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能);
- sbin 目录:存放启动或停止 Hadoop 相关服务的脚本;
- share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例。
环境变量配置
1 | export HADOOP_HOME=/usr/lib/hadoop-2.7.2 |
其中/usr/lib/hadoop-2.7.2应替换为 hadoop 实际安装路径。
测试安装是否成功:
1 | hadoop version |
hadoop 配置文件
hadoop 配置文件都在 hadoop 安装目录下的 etc/hadoop 下,本文用到的四个文件是core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml。在配置文件目录下,有的文件已经存在,直接在里面修改配置;有的文件加了后缀.template,将后缀去掉并修改配置;有的文件可能不存在,需要新建文件并编辑。
除了配置文件,还有几个命令可能需要修改JAVA_HOME路径:hadoop-env.sh、yarn-env.sh、mapred-env.sh。
core-site.xml配置:
1 | <configuration> |
hdfs-site.xml配置:
1 | <configuration> |
yarn-site.xml配置:
1 | <configuration> |
mapred-site.xml配置:
1 | <configuration> |
启动
每次配置完,都要先将四个模块都停下来(将启动命令的 start 替换为 stop),然后清除 data 目录(core-site.xml中配置的目录),再然后格式化 namenode:
1 | hadoop namenode -format |
然后先后执行以下命令以启动NameNode、DataNode、ResourceManager、NodeManager。
1 | sbin/hadoop-daemon.sh start namenode |
执行jsp命令以观察是否有NameNode、DataNode、ResourceManager、NodeManager,如果不全则没有正常启动,应检查 hadoop 和 java 是否正确安装,配置文件是否正确配置,网络和防火墙是否正确设置。
访问localhost:50070可以观察 hadoop 的运行状态。访问192.168.189.128:8088可以观察 yarn 的运行状态,网站要用本机 ip 而不是 localhost。
执行任务
下面执行一个单词个数统计任务。在 hadoop 安装目录下新建一个 wcinput 文件夹,在里面新建一个 wc.input 文件,并追加如下内容:
1 | hadoop yarn |
将 wcinput 文件夹放入 hdfs 根目录下:
1 | hadoop fs -put wcinput / |
执行 MapReduce 程序(此时文件系统为 hdfs):
1 | bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /wcoutput |
运行完毕后,查看运行结果:
1 | hadoop fs -cat /wcoutput/* |
调试出错需要重启时
调试出错需要重启时,先将四个模块都停下来(将启动命令的 start 替换为 stop),然后清除 data 目录(core-site.xml中配置的目录),再然后才可以重新启动,启动时仍要初始化 namenode。
多机模式
多机模式就是真正的集群了,多个主机分别搭载不同的模块。本文采用最简单的 3 个 linux 组成的架构:一个搭载 NameNode,一个搭载 ResourCemamager,一个搭载 SecondaryNameNode,DataNode 和 NodeManager 每个都有。
制造多 linux
本文使用 vm 虚拟机实现多 linux 架构,vm 虚拟机可以在单机模式配置完毕之后创建系统快照,通过直接复制快照的方式对源 linux 系统实现复制,这种方法内存占用少,复制效率高,直接改个别参数就可以实现多 linux 架构。如果是云服务器可能只能一个一个按照单机模式来配置啦。
对于复制快照的形式,要注意这几个 linux 系统的网卡物理地址不能一样,且网络参数需要重新配置一下(设备名、物理地址、IP 可能都要换)。
文件配置
在单机模式提到的四个配置文件中,有几个地方要改:
- core-site.xml 中,NameNode 的地址改为搭载 NameNode 的主机地址;
- hdfs-site.xml 中,个数改为 3,同时增加辅助名称节点配置:
1
2
3
4
5<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property> - yarn-site.xml 中,YARN 的 ResourceManager 的地址改为搭载 ResourceManager 的主机地址。
这三点改动需要同时应用在三个 linux 中。
除了配置文件的改动,还需要配置 etc 下的 hosts 文件,加入三个 linux 的主机地址和主机名的映射关系。主机名设为不同。这是由于 hadoop 的某些程序只认主机名。
手动启动 NameNode 和 DataNode
启动前一定要确保 data 目录已清除,各主机可以通过主机名 ping 通。
将搭载 NameNode 的主机按启动流程启动,通过 jps 命令查看所有节点是否均正常启动。如正常,然后将剩余两台主机的 DataNode 启动。访问搭载 NameNode 的主机的 50070 端口观察 hadoop 集群的运行状态。在 Datanodes 栏观察是否成功出现 3 个 DataNode。
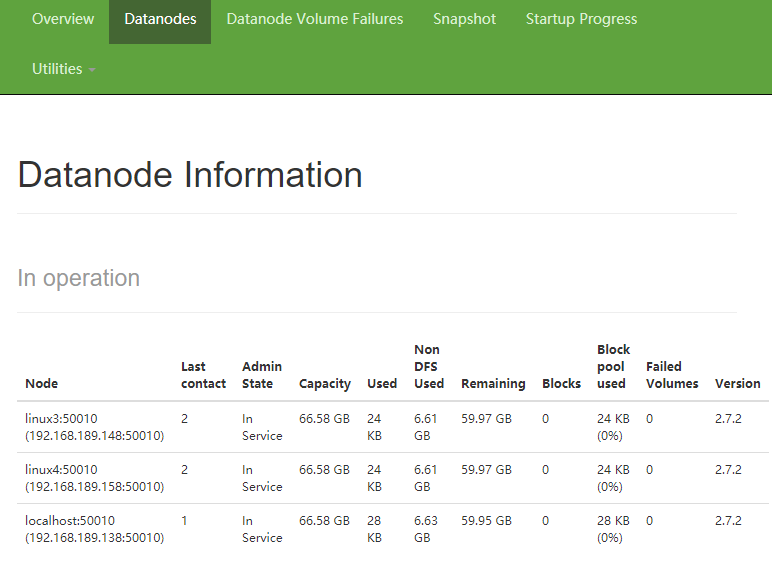
Datanodes栏
如果没有正确出现多个 DataNode,可以通过 jps 命令或查看日志的方式看看是什么地方有错。
如果出现了 3 个,那么恭喜你,成功就在眼前!!
自动启动
首先在三个 linux 的 hadoop 目录下的 etc/hadoop 配置文件目录下编辑 slaves 文件。这个文件存放从属主机名,将原先的 localhost 改为三个主机的主机名,一行显示一个。需要注意的是,不许有空格或空行。
接下来启动 hdfs,在搭载 NameNode 的主机 hadoop 目录下执行:
1 | sbin/start-dfs.sh |
接下来启动 yarn,在搭载 ResourceManager 的主机 hadoop 目录下执行:
1 | sbin/start-yarn.sh |
可以在搭载 ResourceManager 的主机的 8088 端口看看是否有页面,如果有,在页面的 nodes 栏看看是否有三个正在运行的节点,如果有,则说明 ResourceManager 自动配置成功。
可以在搭载 SecondaryNameNode 的主机的 50090 端口看看是否有页面,如果有,则说明 SecondaryNameNode 自动配置成功。
接下来可以看看单机模式下的统计单词数量任务是否可以在多机模式下完成,如果可以,那你就通关啦!!
集群停止方法
整体停止 HDFS
1 | stop-dfs.sh |
整体停止 YARN
1 | stop-yarn.sh |
日志配置
为了查看程序的历史运行情况,需要配置历史服务器。在历史服务器,可以看到各任务的具体实施情况。内有日志聚合功能,应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。可以方便的查看到程序运行详情,方便开发调试。
配置
mapred-site.xml文件中,追加如下内容:
1 | <!-- 历史服务器端地址 --> |
yarn-site.xml文件中,追加如下内容:
1 | <!-- 日志聚集功能使能 --> |
需要同时在三个 linux 上追加。追加历史服务器相关配置不需要格式化 NameNode。将当前模块都停止,然后再启动。启动后在搭载 NameNode 的主机 hadoop 目录下执行如下命令以启动历史服务器:
1 | sbin/mr-jobhistory-daemon.sh start historyserver |
再次执行统计单词数量任务,然后在搭载 NameNode 的主机的 19888 端口可以看到历史任务,单击 JobID 上的链接到具体任务,再单击 logs 就可以看到聚合日志。