
第六章 进程调度
6.1 进程调度的目标有哪些?
响应速度尽可能快;
进程处理的时间尽可能短;
系统吞吐量尽可能大;
资源利用率尽可能高;
对所有进程要公平;
避免饥饿;
避免死锁。
6.2 进程调度的7个目标中,你觉得windows或Linux重点在于满足哪些目标?为什么这么认为?
个人觉得与操作系统是linux还是windows关系不大,每种操作系统都有不同的版本用于不同的需求,如果偏向服务器会要求系统吞吐量、资源利用率高,如果偏向家庭办公的多任务交互场景会要求响应快、避免饥饿。windows有家庭版、工作站版等版本,linux也有很多版本,甚至可以自己修改内核。
6.3 什么是周转时间,什么是带权周转时间?
周转时间是指进程提交给计算机到最终用完成所花费的时间,说明了进程在系统中停留时间的长短。
带权周转时间是指进程的周转时间与运行时间的比值,说明了进程在系统的相对停留时间。
6.4 什么是响应比?响应比高者优先调度算法有什么特点?
响应比是指作业的响应时间与运行时间的比值,响应时间为等待时间加运行时间。
相同等待时间,运行时间越短的作业响应比越高;相同作业时间,等待时间越长的作业响应比越高。
响应比高者优先调度算法有利于短作业和等候长的作业。
6.5 试述优先数调度的算法概念?何为静态优先数,何为动态优先数?
优先数调度算法根据进程的优先数,把CPU分配给最高的进程。
进程优先数等于静态优先数加动态优先数。
静态优先数在创建进程时确定,基于进程所需的资源多少、运行时间长短、进程类型(IO/CPU、前台/后台、核心/用户)。
动态优先数在进程运行期间可以改变,基于使用CPU时长、I/O操作、等待时长。
6.6 静态优先数如何确定的?譬如:进程所需的资源多(或少),就分配较小(或较多)的静态优先数?
1、进程所需的资源多,就分配较小的静态优先数,降低优先级,降低进程占用CPU时间;
2、基于程序运行时间的短,分配较多静态优先数,提高优先级,优先使用CPU;
3、进程的类型[IO/CPU,前台/后台,核心/用户],核心进程分配较多优先数优先运行,用户进程分配优先数少排队运行。
6.7 动态优先数如何确定的?譬如:当使用CPU超过一定时长时,就减少(或增加)的动态优先数?
与静态优先数的理念相同,本质上都是在基于进程类型分配优先级,额外处理了静态优先级可能存在的饥饿现象。
1、当使用CPU超过一定时长时,就减少的动态优先数,降低进程优先级,目的是保证不阻碍其他IO任务的处理;
2、当进行I/O操作后,就增加的动态优先数,主观上认为这个进程可能与IO操作有关,日后大概率还会需要IO操作提高进程优先级进程I/O操作;
3、当进程等待超过一定时长时,就增加的动态优先数,处理了可能出现的饥饿现象。
6.8 试述循环轮转调度的概念和其优点。
循环轮转调度是指把所有就绪进程按先进先出的原则排成队列,所有进程按时间片为单位轮流使用CPU,运行过但没结束的进程排队到队列末尾,等候下一轮运行。
该调度方式保证了进程调度的公平性和交互性。
6.9 Linux创建子进程时,其COUNTER值为什么只继承父进程的一半,原因何在?
为保证进程调度的对所有进程要公平的原则。如果一个进程的子进程都按照父进程的COUNTER值继承,那该进程理论上可以通过无限创建子进程的方式长期占用CPU资源,不利于系统正常运行。
6.10 描述Linux(以早期的0.11内核为参考)两个进程A,B切换的基本过程。
进程切换时,首先是保护现场,中断程序调用了schedule(),其中的switch_to做了进程上下文切换,执行完毕后再恢复现场,中断返回。
进程切换switch_to()源代码:
1 | /****************************************************************************/ |
主要流程是判断当前任务是否是要切换的任务,是则跳到标号1,即不做任何事;交换;调整等。。。
比较关键的是_TSS(n) 和ljmp %0。
第7行是理解任务切换机制的关键。长跳转至 &tmp,造成任务的切换。AT&T语法的ljmp相当于Intel语法的 jmp far SECTION : OFFSET,在这里就是将(IP)<-tmp.a,(CS)<-tmp.b,它的绝对地址之前加星号(”“)。当段间指令jmp所含指针的选择符指示一个可用任务状态段的TSS描述符时,将造成任务切换。那么CPU怎么识别描述符是TSS描述符而不是其他描述符呢?这是因为所有描述符(一个描述符是64位)中都有4位用来指示该描述符的类型,如描述符类型值是9或11都表示该描述符是TSS描述符。好了,CPU得到TSS描述符后,就会将其加载到任务寄存器TR中,然后根据TSS描述符的信息(主要是基址)找到任务的tss内容(包括所有的寄存器信息,如eip),根据其内容就可以开始新任务的运行。我们暂且把这个恢复所有寄存器状态的过程称为恢复寄存器现场。在第7行执行后,完成任务切换(即切换到新的任务里执行);当任务切换回来后才会继续执行第8行!下面详解其原因。既然任务切换时CPU会恢复寄存器现场,那么它当然也会保存寄存器现场了。这些寄存器现场都会被写入原任务的tss结构里,值得注意的是,EIP会指向引起任务切换指令(第7行)的下一条指令(第8行),所以,很明显,当原任务有朝一日再次被调度运行时,它将从EIP所指的地方(第8行)开始运行。
ljmp %0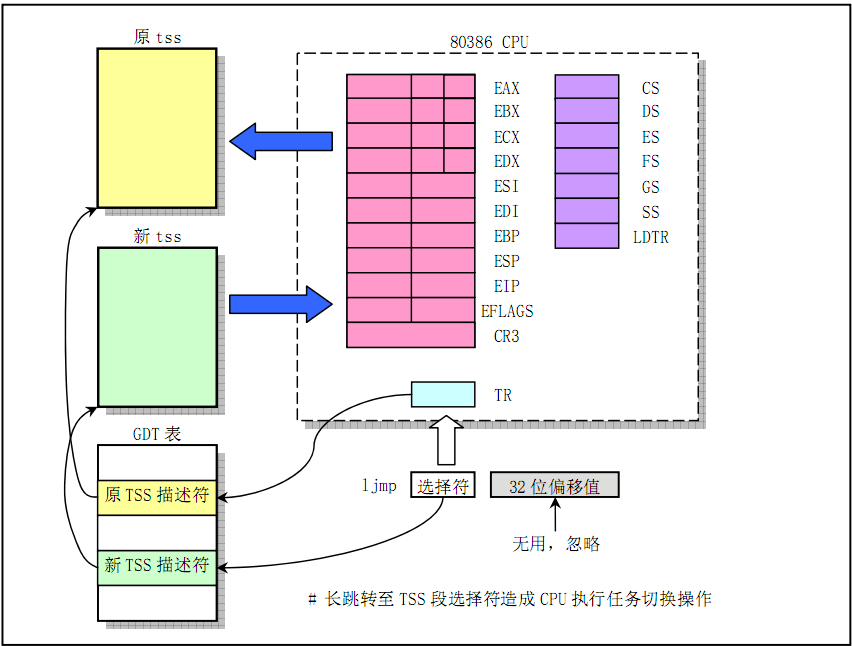
6.11 描述Linux(以早期的0.11内核为参考)中普通进程的调度过程。
linux系统中,一个进程有5种可能状态,在sched.c第19行处定义了状态的标识:
1 | #define TASK_RUNNING 0 // 正在运行或可被运行状态 |
各种状态的转换图如下:
状态的转换图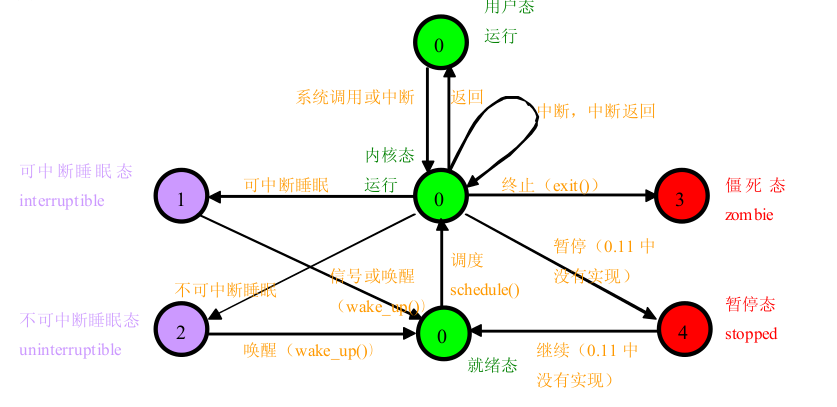
普通进程的调度发生在用户态。当时钟中断产生时,如果进程运行在用户态时并且时间片用完,中断处理函数do_timer()会调用schedule()函数,这相当于用户态的运行被抢断了。如果进程处在内核态时发生时钟中断,do_timer()不会调用schedule()函数,也就是内核态是不能被抢断的。当一个进程运行在内核态,除非它自愿调用schedule()函数而放弃CPU的使用权,它将永远占用CPU。由于schedule()不是系统调用,用户程序不能调用,所以在时钟中断中调用schedule()是必要的,这样保证用户态的程序不会独占CPU。
schedule()函数代码如下:
1 | /****************************************************************************/ |
当前进程只有调用了schedule()后才能发生进程切换,因此当进程再次被选中执行后,都是从switch_to()中ljmp后一条语句开始执行,即从”cmpl %%ecx,last_task_used_math/n/t”语句继续,这时进程位于内核态。因此进程从就绪态进入的都是内核运行态。但有一个例外,进程产生后第一次被调度执行。
fork()产生的子进程会把父进程原cs、原eip当作初始的cs、eip,所以子进程刚刚创建时处于用户态。第一次进程被调度时,从就绪态进入的是用户运行态。以后进入的都是内核运行态。